
Table of Contents
- Integration
- 5 Key Capabilities of Kafka
- Used Stack
- One new NPM Package
- Get Started with a New Kafka Cluster
- Login and create an Upstash Kafka Cluster
- Adding Env-Variables in .env.local
- Fetch Request Details in middleware.ts
- Complete Middleware.ts file
- Startup Dev Environment
- Adding Table to Prisma Schema
- API Route for reading Kafka messages
- API Route for sending data to Postgres
- Calling the endpoint
- Cloudapp-dev, and before you leave us
Upstash Kafka is an ideal solution for website analytics due to its serverless architecture, which eliminates the need to manage infrastructure and reduces operational complexity and costs. Its pay-as-you-go pricing ensures scalability, making it suitable for both small and large-scale applications. Upstash Kafka offers a high throughput and low latency, which is crucial for real-time data processing and analytics.
Integration
Its integration capabilities with various data sources and analytics tools streamline the data pipeline, enabling seamless ingestion, processing, and analysis. Additionally, Upstash Kafka ensures data durability and reliability with its distributed architecture, ensuring that analytics data is consistently available. The ease of use, coupled with robust security features, makes Upstash Kafka a reliable and efficient choice for handling large volumes of website analytics data, providing actionable insights to drive business decisions.
5 Key Capabilities of Kafka
Real-Time Data Processing: Kafka excels in real-time data processing, enabling businesses to perform analytics on live data streams, which is essential for timely insights and decision-making.
Scalability and Fault Tolerance: Kafka’s distributed architecture allows for seamless scalability and robust fault tolerance, ensuring reliable data ingestion and analytics even as data volumes grow.
High Throughput and Low Latency: Kafka is designed for high throughput and low latency, making it ideal for analytics applications that require quick data ingestion and immediate processing.
Integration with Analytics Tools: Kafka integrates seamlessly with various analytics tools and platforms, such as Apache Spark and Apache Flink, enhancing its capabilities for comprehensive data analysis.
Efficient Data Storage and Retrieval: Kafka’s efficient data storage and retrieval mechanisms support large-scale data analytics, enabling organizations to store, access, and analyze massive datasets with ease.
By leveraging these advantages, Kafka empowers businesses to enhance their analytics capabilities, leading to more informed decision-making and improved operational efficiency.
Here is the GitHub repo with the entire code, where you can see all the details regarding my Kafka Integration.
Used Stack
I will start with my default stack:
Next.js 14 as the web framework, and I will use the provided middleware edge function
Upstash Kafka, in combination with the NPM Package @upstash/kafka
Neon.tech Serverless Postgres
Vercel for hosting
One new NPM Package
Get Started with a New Kafka Cluster
Setting up a new Kafka cluster is relatively easy. Login to Upstash:
Login and create an Upstash Kafka Cluster
On the top, select “Kafka” and below on the right, “+ Create Cluster”. Select a Cluster name, a region, and the Replica type, and you are done.
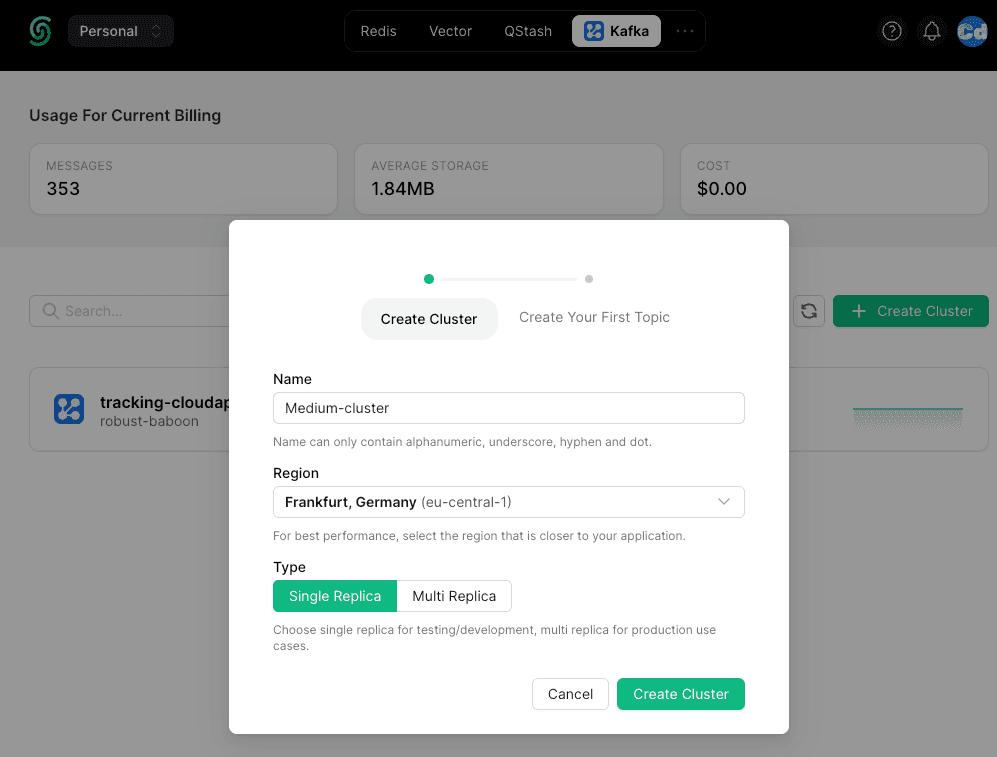
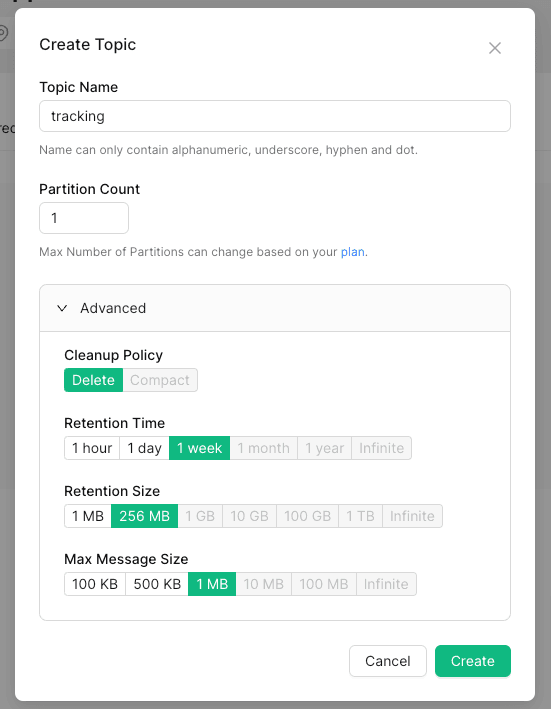
In the second step, create a “Topic,” which is the place where your messages will be stored and where you select the “Cleanup Policy” and the “Retention Settings”.
Getting the needed data for the .env.local
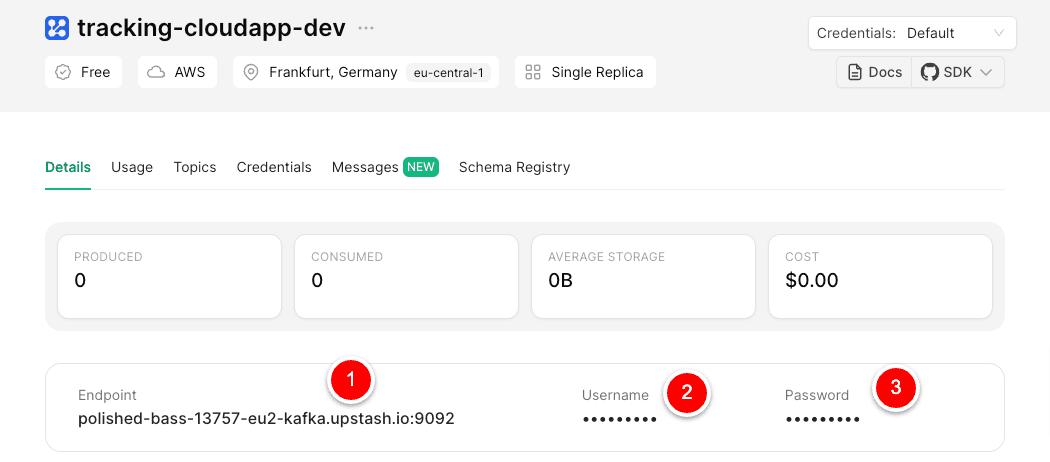
Adding Env-Variables in .env.local
Use the three values copied before for the local .env file
Fetch Request Details in middleware.ts
As a first step, I import the “Kafka” package into the middleware.ts file under src and add “NextFetchEvent” from next/server as well.
Then, I define the connection with the prepared .env variables.
The next step is to add the event to the function definition.
Now, I am ready to get the details from the “request” object and push them to our Kafka Cluster. The first part with the const newDate = xx is used to set the “created_at” attribute in the object messagekafka because I need to add two hours (I am living in CET ;-))
Below the creation of the “messagekafka” object, I start the “producer” and define the “topic” (remember the name that you set up in upstash).
On the last line, I push the data to the cluster.
Complete Middleware.ts file
Startup Dev Environment
Let’s test it with the command
Open your browser and go to the link http://localhost:3000, and you will see messages poping up in your cluster.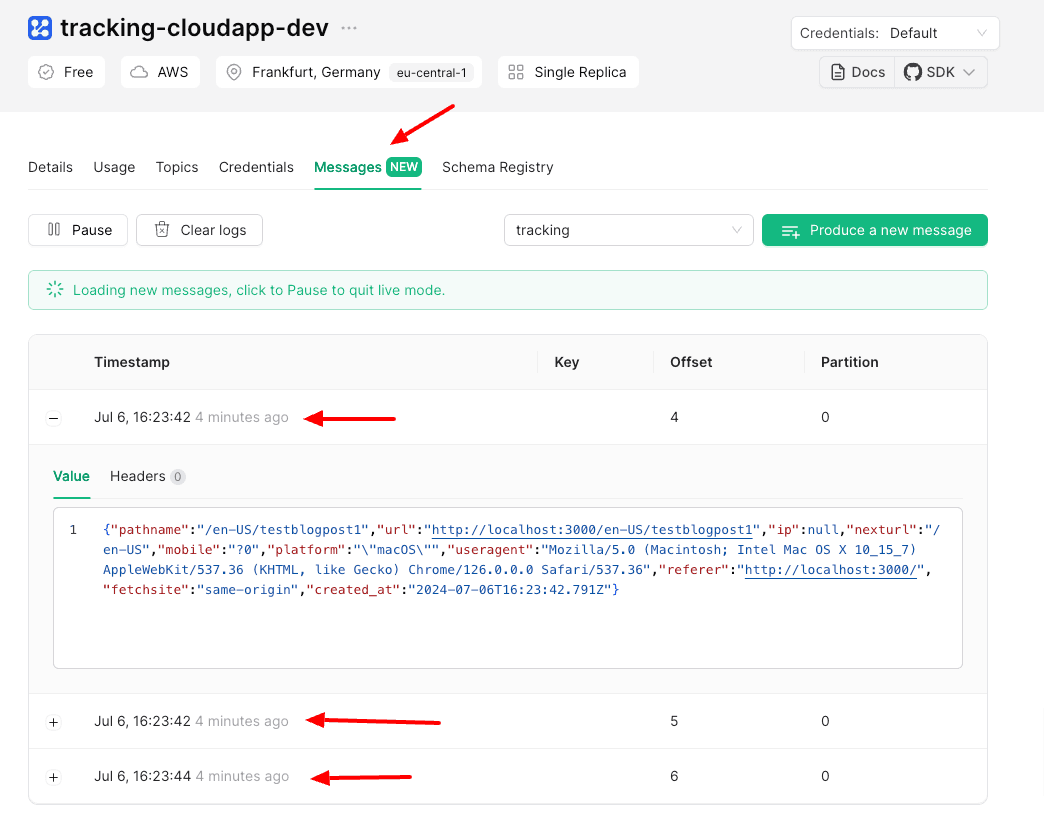
Adding Table to Prisma Schema
The Kafka Connection is up and running. Now, I will create the schema for the new Postgres table in Prisma.
After saving the schema.prisma file under prisma run
Now, you should see the table in the DB schema on neon.tech console.
API Route for reading Kafka messages
Now, I am creating a new API Route for my next Project.
Here, we don’t define a Kafka Producer, as we did in the middleware.ts, but we define a Kafka.consumer to read the messages of a topic. For the “consumerGroupID” and “instanceId” you can specify a random name. It’s used for the offset, which means that if there are more consumers, every consumer should have its own “consumerGroupId” so that it can use its own “offset” when fetching the messages.
API Route for sending data to Postgres
As you probably have seen, I am using the second API Route to send the data to Postgres via Prisma. (src/app/api/user/tracking)
Calling the endpoint
If you now do a POST call to the endpoint:
http://localhost:3000/api/startConsumer
You will get the processed number as response and should see the data in your Postgres Table. Don’t forget to pass the API-Key as header “x-api-key”
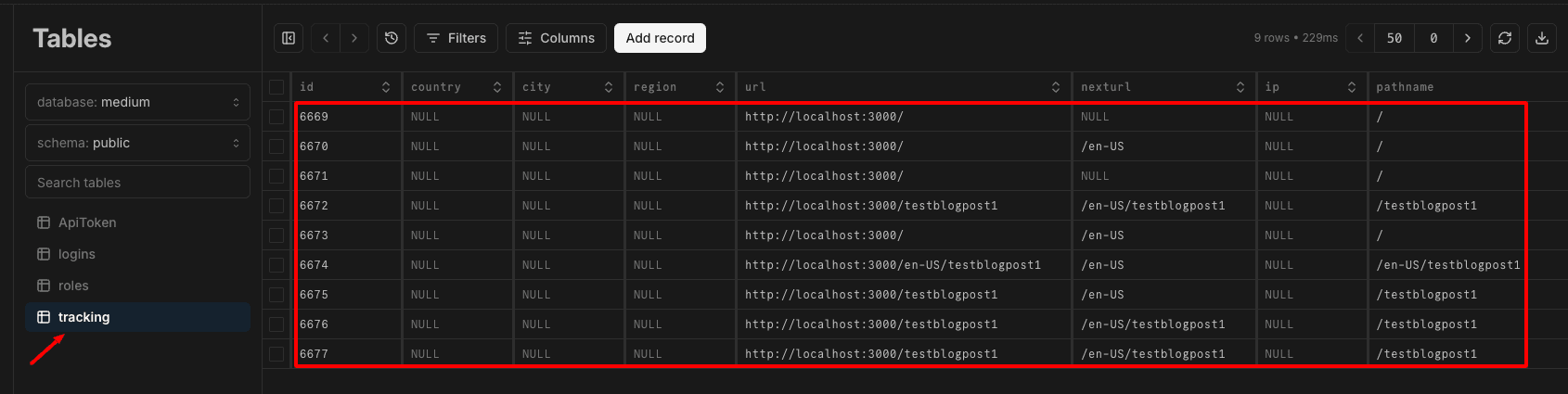
In the following stories, we will go ahead and automate the import to Postgres via Vercel Cron and build an Analytics Dashboard step by step.
Cloudapp-dev, and before you leave us
Thank you for reading until the end. Before you go:

