
Inhaltsverzeichnis
- Integration
- 5 Vorteile von Kafka
- Verwendeter Stack
- One new NPM Package
- Los geht's mit einen neuen Kafka Cluster
- Einloggen und erstellen eines Upstash Kafka Clusters
- Env-Variable in .env.local hinzufügen
- Fetch Request Details in der Datei middleware.ts
- Komplette Middleware.ts Datei
- Starten der Testumgebung
- Tabelle zu Prisma Schema hinzufügen
- API-Route zum Lesen von Kafka-Nachrichten
- API Route für das Übertragen der Daten zu Postgres
- Endpunkt aufrufen
- Cloudapp-dev und bevor Sie uns verlassen
Upstash Kafka ist aufgrund seiner serverlosen Architektur eine ideale Lösung für Website-Analysen, die die Verwaltung der Infrastruktur überflüssig macht und die betriebliche Komplexität und Kosten reduziert. Seine Pay-as-you-go-Preise gewährleisten Skalierbarkeit, wodurch es sich sowohl für kleine als auch für große Anwendungen eignet. Upstash Kafka bietet einen hohen Durchsatz und eine niedrige Latenz, was für die Verarbeitung und Analyse von Daten in Echtzeit entscheidend ist.
Integration
Die Integrationsfunktionen von Upstash Kafka mit verschiedenen Datenquellen und Analysetools rationalisieren die Datenpipeline und ermöglichen eine nahtlose Aufnahme, Verarbeitung und Analyse. Darüber hinaus gewährleistet Upstash Kafka mit seiner verteilten Architektur die Beständigkeit und Zuverlässigkeit der Daten und stellt sicher, dass die Analysedaten stets verfügbar sind. Die Benutzerfreundlichkeit in Verbindung mit robusten Sicherheitsfunktionen macht Upstash Kafka zu einer zuverlässigen und effizienten Wahl für die Verarbeitung großer Mengen von Website-Analysedaten, die verwertbare Erkenntnisse für Geschäftsentscheidungen liefern.
5 Vorteile von Kafka
Echtzeit-Datenverarbeitung: Kafka zeichnet sich durch die Echtzeit-Datenverarbeitung aus und ermöglicht Unternehmen, Analysen auf Live-Datenströmen durchzuführen, was für rechtzeitige Einblicke und Entscheidungen unerlässlich ist.
Skalierbarkeit und Fehlertoleranz: Die verteilte Architektur von Kafka erlaubt eine nahtlose Skalierbarkeit und robuste Fehlertoleranz, was eine zuverlässige Datenaufnahme und Analytik selbst bei wachsenden Datenmengen sicherstellt.
Hoher Durchsatz und geringe Latenz: Kafka ist für hohen Durchsatz und geringe Latenzzeiten konzipiert, was es ideal für Analyseanwendungen macht, die eine schnelle Datenaufnahme und sofortige Verarbeitung erfordern.
Integration mit Analysetools: Kafka integriert sich nahtlos mit verschiedenen Analysetools und Plattformen wie Apache Spark und Apache Flink, wodurch seine Fähigkeiten für umfassende Datenanalysen erweitert werden.
Effiziente Datenspeicherung und -abruf: Die effizienten Mechanismen von Kafka zur Datenspeicherung und -abruf unterstützen groß angelegte Datenanalysen und ermöglichen es Organisationen, massive Datensätze problemlos zu speichern, zuzugreifen und zu analysieren.
Durch die Nutzung dieser Vorteile ermöglicht Kafka Unternehmen, ihre Analysefähigkeiten zu verbessern, was zu fundierteren Entscheidungen und einer verbesserten Betriebseffizienz führt.
Hier ist das GitHub-Repository mit dem gesamten Code, wo Sie alle Details zu meiner Kafka-Integration sehen können.
Verwendeter Stack
Ich beginne mit meinem Standard-Stack:
Next.js 14 als Web-Framework, und ich werde die bereitgestellte Middleware-Edge-Funktion verwenden
Upstash Kafka in Kombination mit dem NPM-Paket @upstash/kafka
Neon.tech Serverless Postgres
Vercel für das Hosting
One new NPM Package
Los geht's mit einen neuen Kafka Cluster
Der Setupprozess ist sehr einfach. Anmelden bei Upstash:
Einloggen und erstellen eines Upstash Kafka Clusters
Wählen Sie oben "Kafka" und unten rechts "+ Cluster erstellen". Wählen Sie einen Clusternamen, eine Region und den Replikat-Typ, und schon sind Sie fertig.
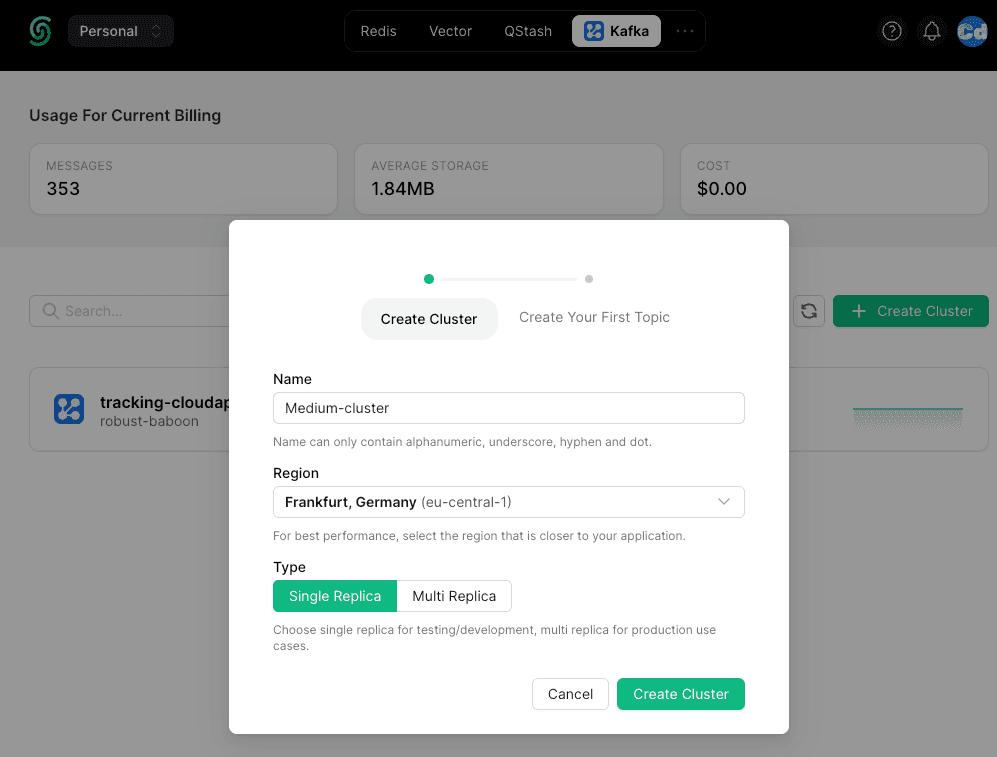
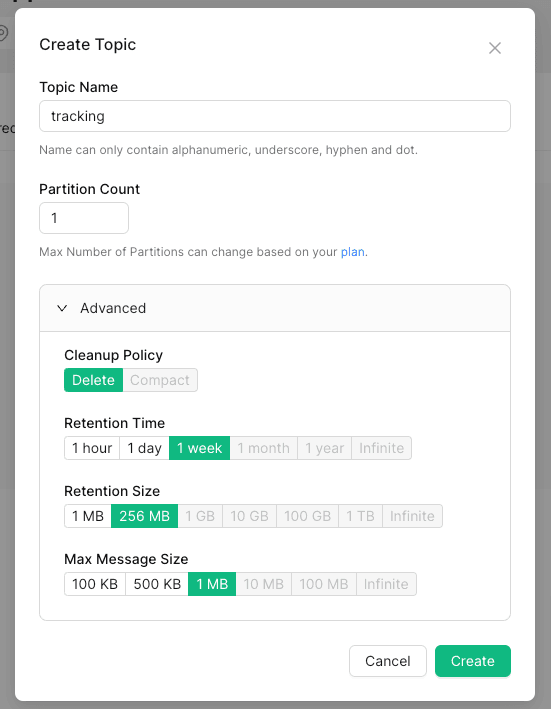
Im zweiten Schritt erstellen Sie ein "Thema", in dem Ihre Nachrichten gespeichert werden und in dem Sie die "Bereinigungsrichtlinie" und die "Aufbewahrungseinstellungen" auswählen.
Abrufen der benötigten Daten für die .env.local
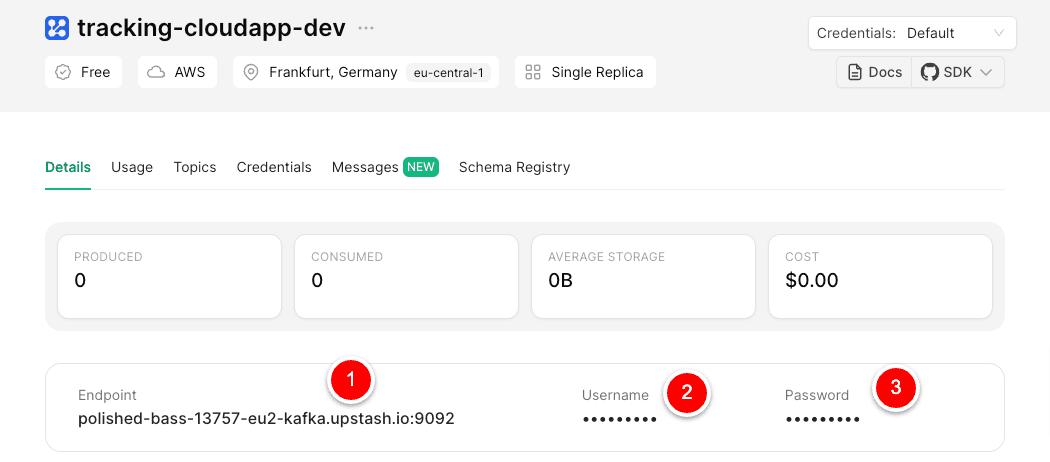
Env-Variable in .env.local hinzufügen
Verwenden Sie die zuvor kopierten drei Werte für die lokale .env-Datei.
Fetch Request Details in der Datei middleware.ts
Als ersten Schritt importiere ich das „Kafka“-Paket in die Datei middleware.ts unter src und füge auch „NextFetchEvent“ von next/server hinzu.
Dann definiere ich die Verbindung mit den vorbereiteten .env-Variablen.
Der nächste Schritt besteht darin, das Ereignis zur Funktionsdefinition hinzuzufügen.
Jetzt bin ich bereit, die Details aus dem „request“-Objekt abzurufen und sie in unser Kafka-Cluster zu pushen. Der erste Teil mit const newDate = xx wird verwendet, um das Attribut „created_at“ im Objekt messagekafka zu setzen, weil ich zwei Stunden hinzufügen muss (ich lebe in der Mitteleuropäischen Zeit ;-)).
Unterhalb der Erstellung des „messagekafka“-Objekts starte ich den „producer“ und definiere das „topic“ (denken Sie an den Namen, den Sie in Upstash eingerichtet haben).
On the last line, I push the data to the cluster.
Komplette Middleware.ts Datei
Starten der Testumgebung
Testen wir es mit dem Befehl
Öffnen Sie Ihren Browser und gehen Sie zu dem Link http://localhost:3000. Sie werden sehen, dass Nachrichten in Ihrem Cluster erscheinen.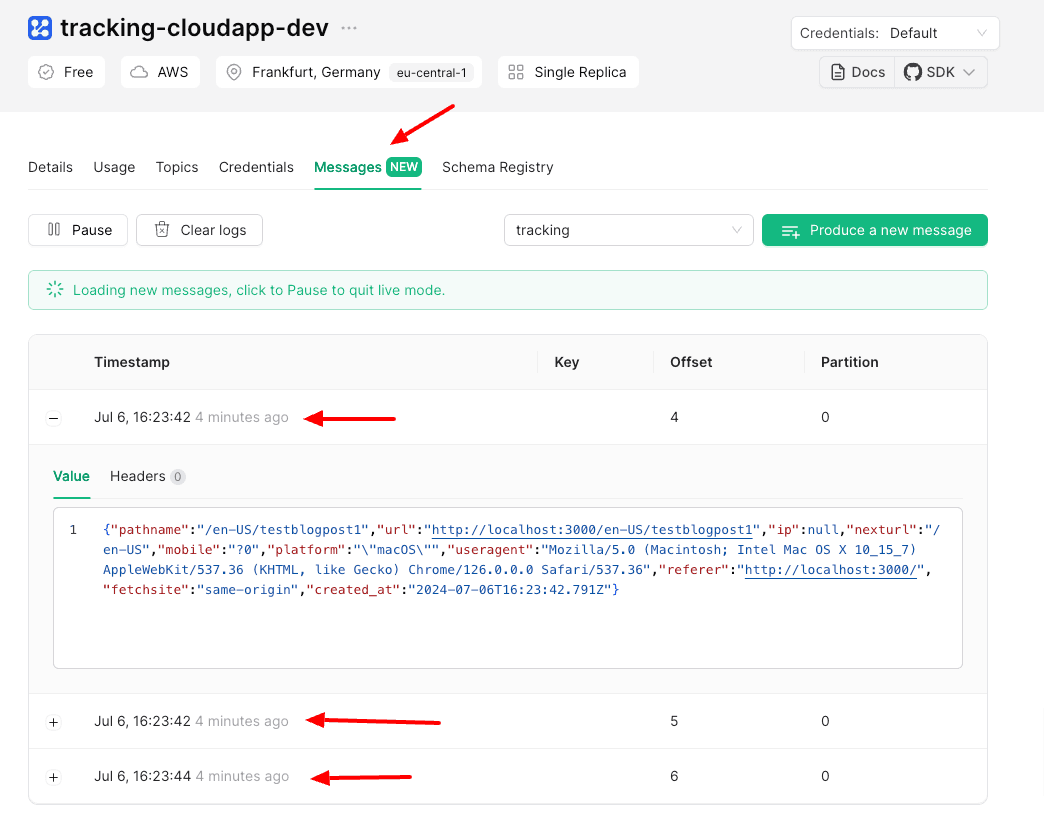
Tabelle zu Prisma Schema hinzufügen
Die Kafka-Verbindung ist aktiv und läuft. Jetzt werde ich das Schema für die neue Postgres-Tabelle in Prisma erstellen.
Nachdem Sie die Datei schema.prisma unter prisma gespeichert haben, führen Sie den Befehl aus:
Jetzt sollten Sie die Tabelle im DB-Schema in der neon.tech-Konsole sehen.
API-Route zum Lesen von Kafka-Nachrichten
Jetzt erstelle ich eine neue API-Route für mein nächstes Projekt.
Hier definieren wir keinen Kafka Producer, wie wir es in der middleware.ts gemacht haben, sondern einen Kafka.consumer, um die Nachrichten eines Themas zu lesen. Für die „consumerGroupID“ und „instanceId“ können Sie einen beliebigen Namen angeben. Diese werden für den Offset verwendet, was bedeutet, dass, wenn es mehrere Konsumenten gibt, jeder Konsument seine eigene „consumerGroupId“ haben sollte, damit er seinen eigenen „Offset“ beim Abrufen der Nachrichten verwenden kann.
API Route für das Übertragen der Daten zu Postgres
Wie Sie wahrscheinlich gesehen haben, verwende ich die zweite API-Route, um die Daten über Prisma an Postgres zu senden. (src/app/api/user/tracking)
Endpunkt aufrufen
Wenn Sie jetzt einen POST-Aufruf an den Endpunkt machen:
http://localhost:3000/api/startConsumer
Sie erhalten die verarbeitete Nummer als Antwort und sollten die Daten in Ihrer Postgres-Tabelle sehen. Vergessen Sie nicht, den API-Schlüssel als Header „x-api-key“ zu übergeben.
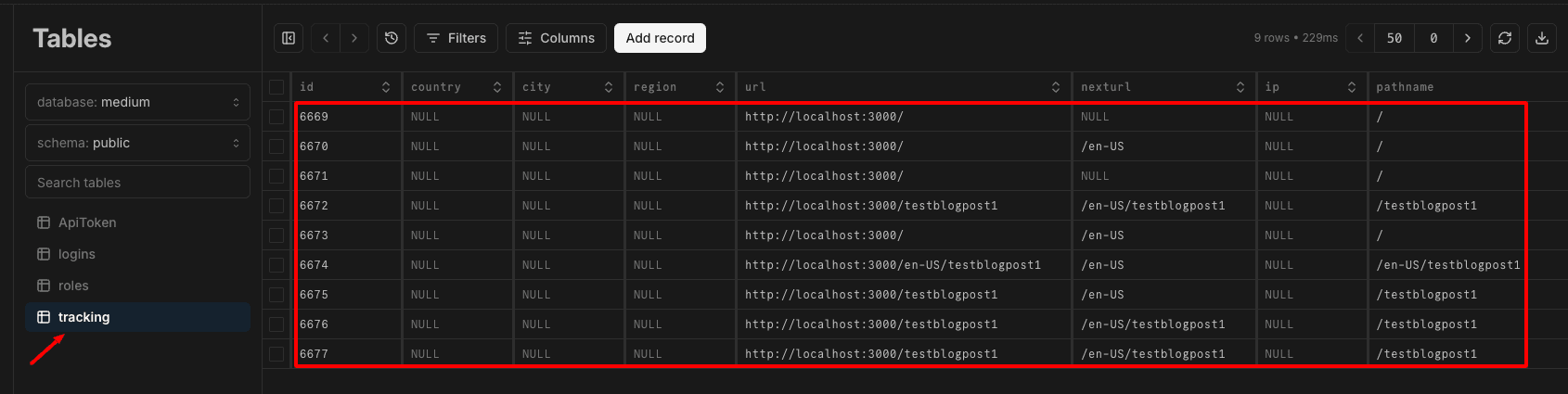
In den folgenden Blogposts werden wir den Import nach Postgres über Vercel Cron automatisieren und ein Analytics-Dashboard Schritt für Schritt erstellen.
Cloudapp-dev und bevor Sie uns verlassen
Danke, dass Sie bis zum Ende gelesen haben. Noch eine Bitte bevor Sie gehen:

